
Dataloading-Engine
Gato GraphQL verwendet serverseitige Komponenten, um das Datenmodell darzustellen (keine Graphen oder Bäume). Schauen wir uns an, wie der Datenladevorgang zur Auflösung der GraphQL-Query abläuft.
Um die Daten zu verarbeiten, müssen wir die Komponenten in Typen umwandeln (<FeaturedDirector> => Director, <Film> => Film, <Actor> => Actor), sie in der Reihenfolge ihres Auftretens in der Komponentenhierarchie ordnen (Director, dann Film, dann Actor) und sie in „Iterationen" behandeln, wobei die Objektdaten für jeden Typ in einer eigenen Iteration abgerufen werden, so:

Die Dataloading-Engine des Servers muss den folgenden (Pseudo-)Algorithmus implementieren, um die Daten zu laden:
Vorbereitung:
- Eine leere Warteschlange anlegen, um die Liste der IDs der Objekte zu speichern, die aus der Datenbank abgerufen werden müssen, geordnet nach Typ (jeder Eintrag lautet:
[type => Liste von IDs]) - Die ID des hervorgehobenen Regisseur-Objekts abrufen und in der Warteschlange unter dem Typ
Directorablegen
Schleife, bis keine Einträge mehr in der Warteschlange sind:
- Den ersten Eintrag aus der Warteschlange holen: den Typ und die Liste der IDs (z. B.:
Directorund[2]), und diesen Eintrag aus der Warteschlange entfernen - Mit dem
TypeDataLoader-Objekt des Typs eine einzelne Query gegen die Datenbank ausführen, um alle Objekte dieses Typs mit diesen IDs abzurufen - Falls der Typ relationale Felder hat (z. B.: Typ
Directorhat das relationale Feldfilmsvom TypFilm), alle IDs dieser Felder aus allen in der aktuellen Iteration abgerufenen Objekten sammeln (z. B.: alle IDs im Feldfilmsaus allen Objekten vom TypDirector) und diese IDs in der Warteschlange unter dem entsprechenden Typ ablegen (z. B.: IDs[3, 8]unter TypFilm).
Am Ende der Iterationen haben wir alle Objektdaten für alle Typen geladen, so:
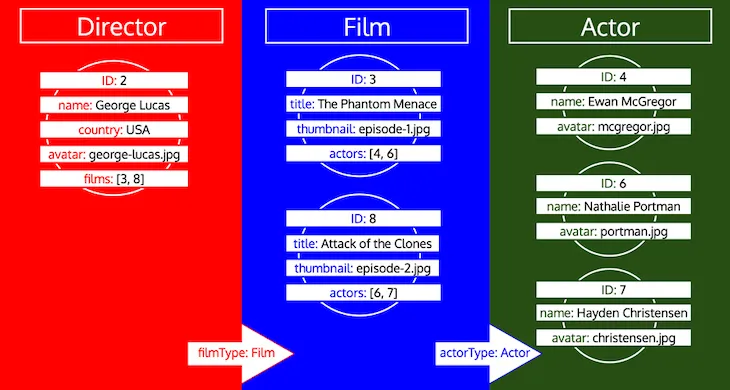
Beachte, wie alle IDs für einen Typ gesammelt werden, bis der Typ in der Warteschlange verarbeitet wird. Wenn wir zum Beispiel ein relationales Feld preferredActors zum Typ Director hinzufügen, würden diese IDs in der Warteschlange unter dem Typ Actor abgelegt und zusammen mit den IDs aus dem Feld actors des Typs Film verarbeitet:
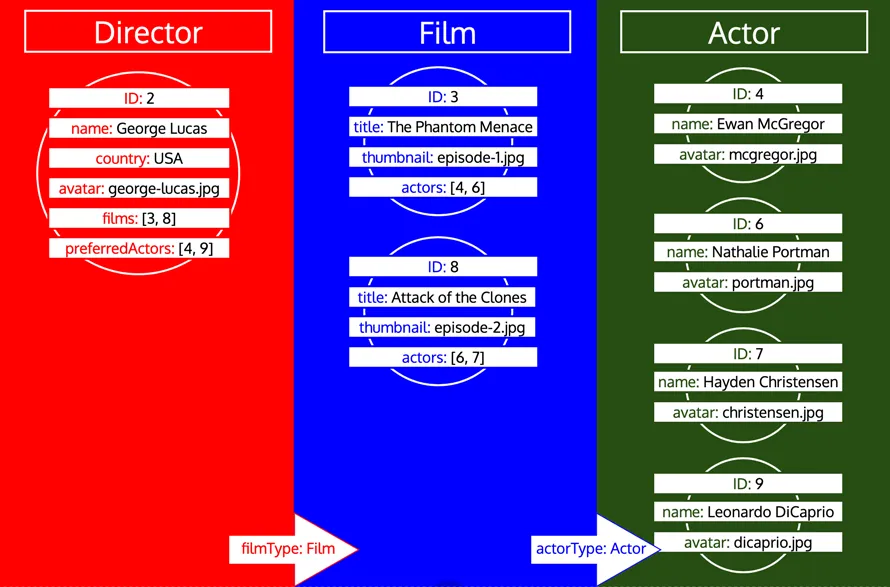
Wenn ein Typ jedoch bereits verarbeitet wurde und danach weitere Daten dieses Typs geladen werden müssen, ist das eine neue Iteration für diesen Typ. Wenn zum Beispiel ein relationales Feld preferredDirector zum Typ Author hinzugefügt wird, wird der Typ Director erneut zur Warteschlange hinzugefügt:
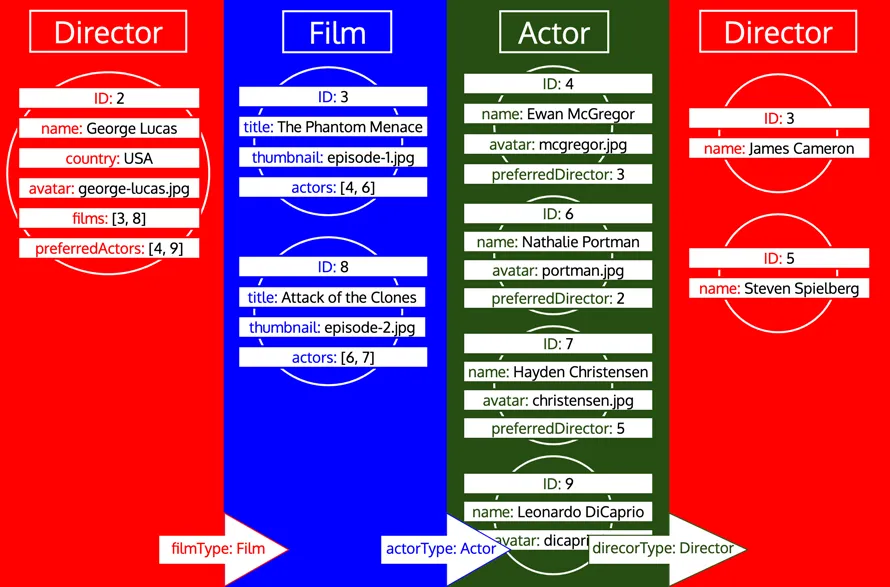
Nachdem wir alle Objektdaten abgerufen haben, müssen wir sie in die erwartete Antwortform bringen, die die GraphQL-Query widerspiegelt. Wie zu sehen ist, haben die Daten jedoch nicht die erforderliche Baumstruktur. Stattdessen enthalten relationale Felder die IDs des verschachtelten Objekts und emulieren damit die Darstellung von Daten in einer relationalen Datenbank. Daher können die für jeden Typ abgerufenen Daten, analog zu diesem Vergleich, als Tabelle dargestellt werden, so:
Tabelle für Typ Director:
| ID | name | country | avatar | films |
|---|---|---|---|---|
| 2 | George Lucas | USA | george-lucas.jpg | [3, 8] |
Tabelle für Typ Film:
| ID | title | thumbnail | actors |
|---|---|---|---|
| 3 | The Phantom Menace | episode-1.jpg | [4, 6] |
| 8 | Attack of the Clones | episode-2.jpg | [6, 7] |
Tabelle für Typ Actor:
| ID | name | avatar |
|---|---|---|
| 4 | Ewan McGregor | mcgregor.jpg |
| 6 | Nathalie Portman | portman.jpg |
| 7 | Hayden Christensen | christensen.jpg |
Da alle Daten als Tabellen organisiert sind und wir wissen, wie die einzelnen Typen miteinander in Beziehung stehen (d. h. Director referenziert Film über das Feld films, Film referenziert Actor über das Feld actors), kann der GraphQL-Server die Daten problemlos in die erwartete Baumstruktur umwandeln:
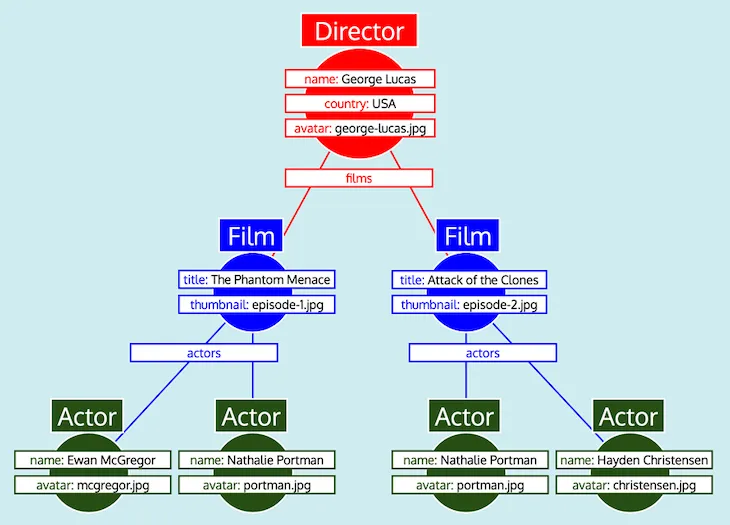
Schließlich gibt der GraphQL-Server den Baum aus, der die Form der erwarteten Antwort hat:
{
data: {
featuredDirector: {
name: "George Lucas",
country: "USA",
avatar: "george-lucas.jpg",
films: [
{
title: "Star Wars: Episode I",
thumbnail: "episode-1.jpg",
actors: [
{
name: "Ewan McGregor",
avatar: "mcgregor.jpg",
},
{
name: "Natalie Portman",
avatar: "portman.jpg",
}
]
},
{
title: "Star Wars: Episode II",
thumbnail: "episode-2.jpg",
actors: [
{
name: "Natalie Portman",
avatar: "portman.jpg",
},
{
name: "Hayden Christensen",
avatar: "christensen.jpg",
}
]
}
]
}
}
}Analyse der Zeitkomplexität der Lösung
Analysieren wir die Big-O-Notation des Datenladealgorithrnus, um zu verstehen, wie die Anzahl der gegen die Datenbank ausgeführten Queries mit der Anzahl der Eingaben wächst, und sicherzustellen, dass diese Lösung performant ist.
Die Dataloading-Engine lädt Daten in Iterationen, die jedem Typ entsprechen. Zu Beginn einer Iteration liegt bereits die vollständige Liste aller IDs aller abzurufenden Objekte vor, sodass eine einzige Query ausgeführt werden kann, um alle Daten der entsprechenden Objekte abzurufen. Daraus folgt, dass die Anzahl der Datenbankabfragen linear mit der Anzahl der in der Query beteiligten Typen wächst. Mit anderen Worten, die Zeitkomplexität ist O(n), wobei n die Anzahl der Typen in der Query ist (wenn ein Typ jedoch mehr als einmal iteriert wird, muss er mehr als einmal zu n gezählt werden).
Diese Lösung ist sehr performant, deutlich besser als die exponentielle Komplexität, die beim Umgang mit Graphen zu erwarten ist, oder die logarithmische Komplexität beim Umgang mit Bäumen.
Implementierter PHP-Code
Der Datenladevorgang findet in der Funktion getComponentData der Klasse Engine im Paket Component Model statt.