
Directive-Pipeline
Directives werden in einer Pipeline angeordnet und der Reihe nach ausgeführt. Ihr ursprüngliches Design ist einfach, etwa so:

In dieser Architektur:
- Der Input der Pipeline ist der Feldwert, der vom Field-Resolver bereitgestellt wird
- Jede Directive führt ihre Logik aus und gibt das Ergebnis an die nächste Directive in der Pipeline weiter
- Der Output der Pipeline ist der aufgelöste Feldwert, der von allen Directives verarbeitet wurde
Diese Architektur nutzt GraphQL jedoch nicht optimal aus. Im Folgenden werden alle Stufen der tatsächlichen Directive-Pipeline beschrieben, bis hin zum in Gato GraphQL implementierten endgültigen Design.
Directives als Bausteine der Query-Auflösung
Zunächst könnte man in Betracht ziehen, den GraphQL-Server das Feld über einen bestimmten Mechanismus auflösen zu lassen und diesen Wert dann als Input an die Directive-Pipeline weiterzugeben.
Es ist jedoch viel einfacher, einen einzigen Mechanismus für alles zu verwenden: Das Aufrufen der Field-Resolver (sowohl zur Validierung als auch zur Auflösung von Feldern) kann bereits über die Directive-Pipeline erfolgen. In diesem Fall ist die Directive-Pipeline der einzige Mechanismus zur Auflösung der Query.
Aus diesem Grund verfügt der Gato GraphQL-Server über zwei spezielle Directives:
@validateruft den Field-Resolver auf, um zu prüfen, ob das Feld aufgelöst werden kann (z. B.: die Syntax ist korrekt, das Feld existiert usw.)- Bei Erfolg ruft
@resolveValueAndMergedann den Field-Resolver auf, um das Feld aufzulösen, und fügt den Wert in das Response-Objekt ein
Diese beiden sind vom speziellen Typ „System"-Directives: Sie sind ausschließlich der GraphQL-Engine vorbehalten und bei jedem Feld implizit vorhanden. (Im Gegensatz dazu sind Standard-Directives explizit: Sie werden vom Nutzer zur Query hinzugefügt.)
Durch die Verwendung dieser beiden Directives wird diese Query:
query {
field1
field2 @directiveA
}...wie folgt aufgelöst:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge @directiveA
}Die Pipeline sieht nun so aus (beachte, dass die Pipeline das Feld als Input erhält, nicht seinen anfänglich aufgelösten Wert):

Pipeline-Slots
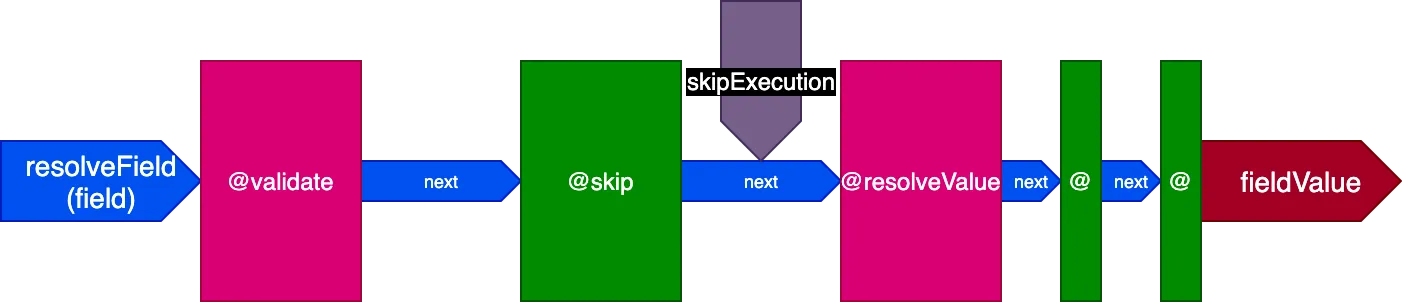
Directives werden normalerweise nach @resolveValueAndMerge ausgeführt, da sie meistens die Aktualisierung des aufgelösten Feldwerts beinhalten. Es gibt jedoch andere Directives, die vor @validate oder zwischen @validate und @resolveValueAndMerge ausgeführt werden müssen.
Zum Beispiel:
- Um die Zeit zu messen, die zum Auflösen eines Felds benötigt wird, kann die Directive
@traceExecutionTimedie aktuelle Zeit vor und nach der Feldauflösung erfassen, indem sie die Sub-Directives@startTracingExecutionTimeam Anfang und@endTracingExecutionTimeam Ende der Pipeline platziert - Eine Directive
@cachemuss prüfen, ob ein angefordertes Feld gecacht ist, und diese Antwort bereits zurückgeben, bevor@resolveValueAndMergeausgeführt wird
Die Pipeline bietet dann fünf verschiedene Slots über die Klasse PipelinePositions, und die Directive gibt an, in welchem sie ausgeführt werden soll:
- Der
"beginning"-Slot: ganz am Anfang - Der
"before-validate"-Slot: vor der Validierung - Der
"middle"-Slot: nach der Validierung und vor der Feldauflösung - Der
"after-resolve"-Slot: nach der Feldauflösung - Der
"end"-Slot: ganz am Ende
Die Directive-Pipeline sieht nun so aus (zur Vereinfachung nur 3 Stufen betrachtet):

Beachte, wie die Directives @skip und @include mit dieser Architektur so einfach umgesetzt werden können: Im "middle"-Slot platziert, können sie die Directive @resolveValueAndMerge (sowie alle Directives in späteren Pipeline-Stufen) anweisen, nicht ausgeführt zu werden, indem sie das Flag skipExecution auf true setzen.
Eine Directive auf mehreren Feldern in einem einzigen Aufruf ausführen
Bisher haben wir ein einzelnes Feld als Input für die Directive-Pipeline betrachtet. Bei einer typischen GraphQL-Query erhalten wir jedoch mehrere Felder, auf denen Directives ausgeführt werden sollen.
In der folgenden Query wird die Directive @upperCase beispielsweise auf den Feldern "field1" und "field2" ausgeführt:
query {
field1 @upperCase
field2 @upperCase
field3
}Da die GraphQL-Engine außerdem die System-Directives @validate und @resolveValueAndMerge zu jedem Feld der Query hinzufügt, sodass diese Query:
query {
field1
field2
field3
}...wie folgt aufgelöst wird:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}Erhalten die System-Directives immer alle Felder als Input.
Daher ist die Directive-Pipeline so konzipiert, dass sie mehrere Felder als Input empfängt und nicht nur eines auf einmal:

Diese Architektur ist effizienter, da das einmalige Ausführen einer Directive für alle Felder schneller ist als das Ausführen für jedes einzelne Feld, und dabei dieselben Ergebnisse liefert.
Wenn beispielsweise geprüft wird, ob der Nutzer angemeldet ist, um Zugriff auf das Schema zu gewähren, kann die Operation nur einmal ausgeführt werden. Das Ausführen des folgenden Codes:
if (isUserLoggedIn()) {
resolveFields([$field1, $field2, $field3]);
}ist effizienter als das Ausführen dieses Codes:
if (isUserLoggedIn()) {
resolveField($field1);
}
if (isUserLoggedIn()) {
resolveField($field2);
}
if (isUserLoggedIn()) {
resolveField($field3);
}Das erscheint beim Aufruf einer lokalen Funktion wie isUserLoggedIn vielleicht nicht bedeutsam, kann aber einen großen Unterschied machen, wenn man mit externen Diensten interagiert, z. B. beim Auflösen von REST-Endpunkten über GraphQL. In diesen Fällen könnte das einmalige Ausführen einer Funktion anstelle mehrerer Male den Unterschied ausmachen, ob eine bestimmte Funktionalität bereitgestellt werden kann oder nicht.
Schauen wir uns ein Beispiel an. Wenn man über eine @translate-Directive mit Google Translate interagiert, muss die GraphQL-API eine Verbindung über das Netzwerk herstellen. Das Ausführen dieses Codes ist so schnell wie möglich:
googleTranslateFields([$field1, $field2, $field3]);Im Gegensatz dazu erzeugt das separate, mehrfache Ausführen der Funktion eine höhere Latenz, die zu längeren Antwortzeiten führt und die Performance der API beeinträchtigt. Für das Übersetzen von 3 Strings (bei denen das Feld der zu übersetzende String ist) ist das vielleicht kein großer Unterschied, aber bei 100 oder mehr Strings hat es sicher einen Einfluss:
googleTranslateField($field1);
googleTranslateField($field2);
googleTranslateField($field3);Außerdem kann das einmalige Ausführen einer Funktion mit allen Inputs eine bessere Antwort liefern als das separate Ausführen der Funktion für jedes Feld. Nimmt man Google Translate wieder als Beispiel, wird die Übersetzung präziser, je mehr Daten wir dem Dienst bereitstellen.
Wenn wir zum Beispiel den folgenden Code ausführen:
googleTranslate("fork");
googleTranslate("road");
googleTranslate("sign");Bei der ersten unabhängigen Ausführung kennt Google den Kontext von "fork" nicht, sodass es als Essgabel, als Straßengabelung oder mit einer anderen Bedeutung übersetzt werden könnte. Wenn wir stattdessen Folgendes ausführen:
googleTranslate(["fork", "road", "sign"]);Aus dieser größeren Informationsmenge kann Google ableiten, dass "fork" sich auf die Straßengabelung bezieht, und eine präzise Übersetzung liefern.
Aus diesen Gründen empfangen die Directives in der Pipeline alle Eingabefelder zusammen, und jede Directive kann dann entscheiden, wie sie ihre Logik am besten auf diese Inputs anwendet (eine einzelne Ausführung pro Input, eine einzelne Ausführung für alle Inputs zusammen oder etwas dazwischen).
Die Pipeline sieht nun so aus:
Eine einzelne Directive-Pipeline für die gesamte Query ausführen
Wir haben gerade gelernt, dass es sinnvoll ist, mehrere Felder pro Directive auszuführen, aber das funktioniert gut, solange alle Felder dieselben Directives angewendet haben. Wenn die Directives unterschiedlich sind, kann dies zu einer größeren Komplexität führen, die die Implementierung erschwert und einige der erzielten Vorteile verringern würde.
Schauen wir uns an, wie das passiert. Betrachten wir die folgende Query:
query {
field1 @directiveA
field2
field3
}Diese Directive ist äquivalent zu dieser:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}In diesem Szenario haben field2 und field3 dieselbe Menge an Directives, und field1 hat eine andere; wir müssten dann 2 verschiedene Pipelines erzeugen, um die Query aufzulösen:
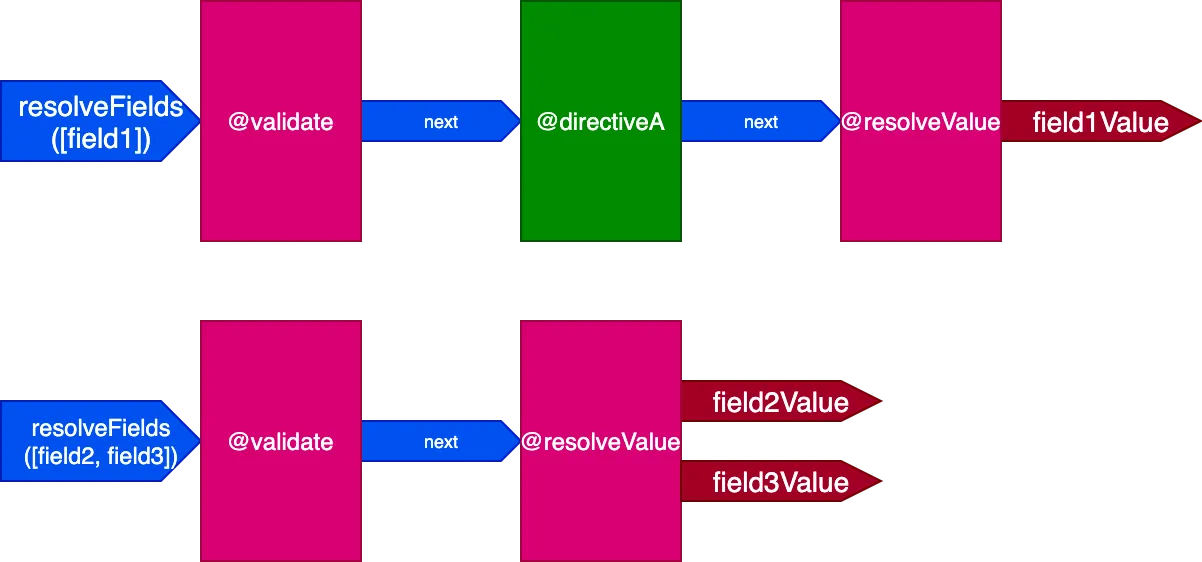
Und wenn alle Felder eine einzigartige Menge an Directives haben, ist der Effekt noch ausgeprägter. Betrachten wir diese Query:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}Die äquivalent zu dieser ist:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge @directiveB @directiveC
field3 @validate @resolveValueAndMerge @directiveC
}In dieser Situation haben wir 3 Pipelines für 3 Felder, so:
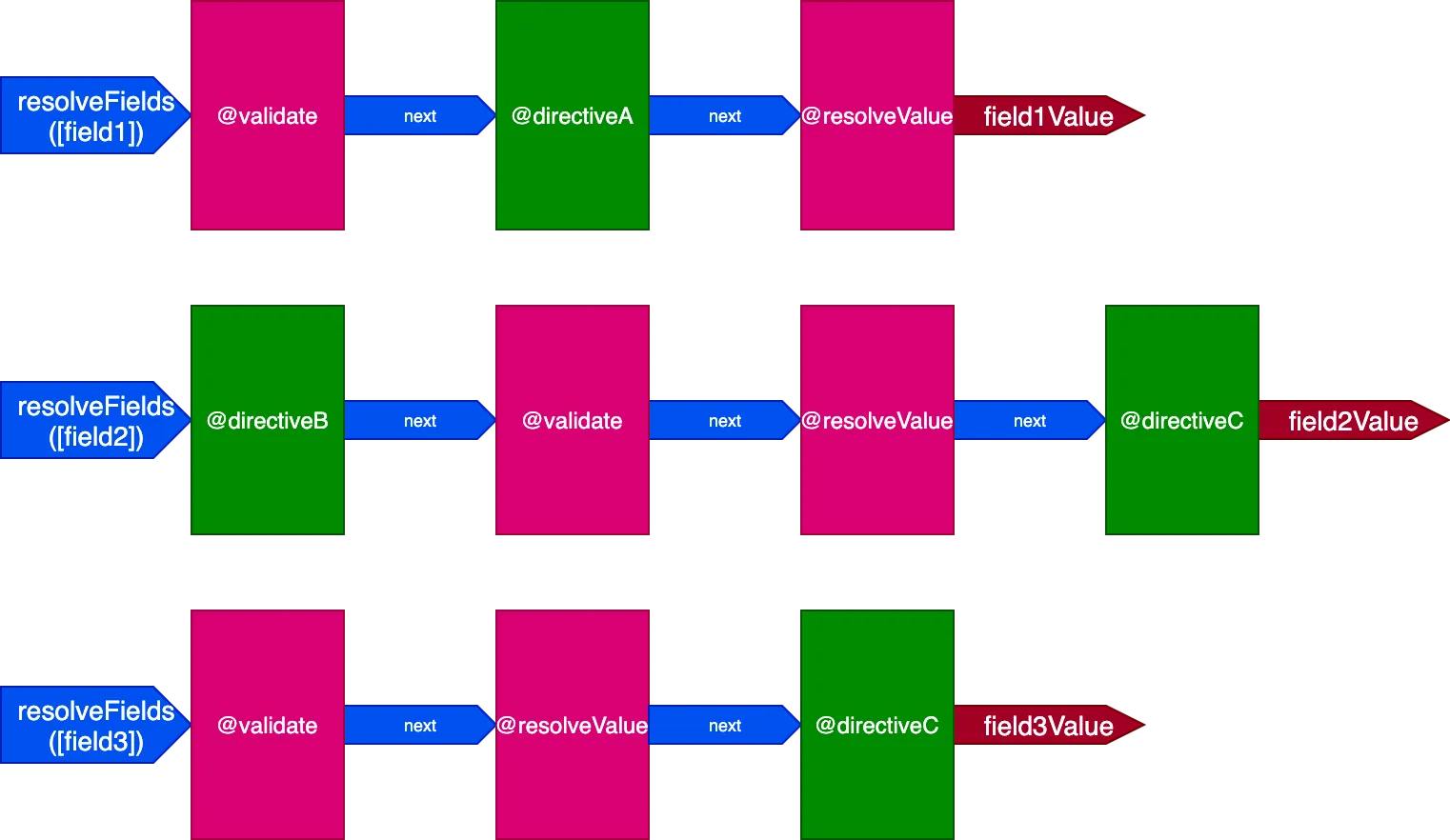
In diesem Fall werden die Directives @validate und @resolveValueAndMerge zwar auf alle 3 Felder angewendet, aber da sie über 3 verschiedene Directive-Pipelines ausgeführt werden, werden sie unabhängig voneinander ausgeführt, was uns wieder dahin bringt, dass eine Directive auf jeweils nur ein Element ausgeführt wird.
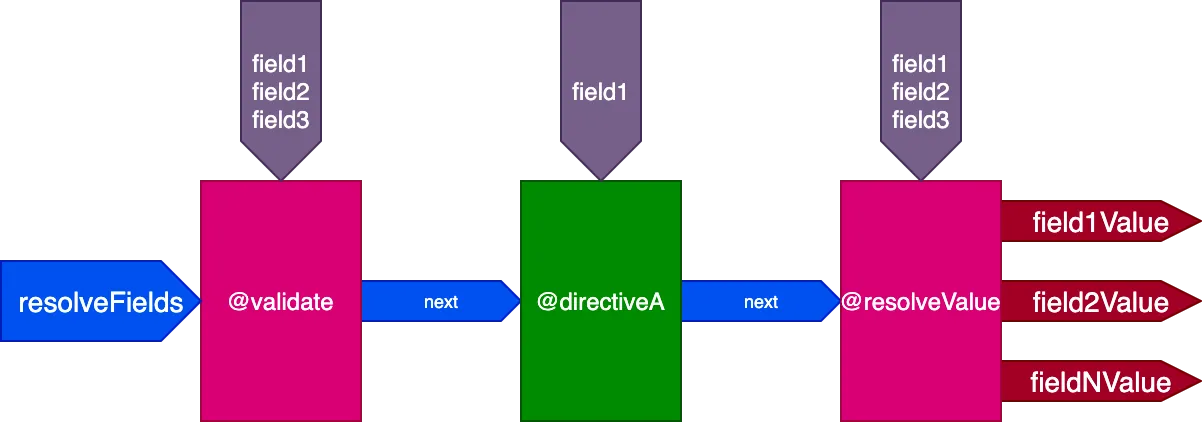
Die Lösung für dieses Problem besteht darin, die Erzeugung mehrerer Pipelines zu vermeiden und stattdessen mit einer einzigen Pipeline für alle Felder zu arbeiten. Infolgedessen übergibt die Engine die Felder nicht mehr als Input an die Pipeline, da nicht alle Directives einer einzigen Pipeline mit derselben Menge von Feldern interagieren; stattdessen muss jede Directive ihre eigene Feldliste als eigenen Input erhalten.
Dann erhalten für diese Query:
query {
field1 @directiveA
field2
field3
}...die Directives @validate und @resolveValueAndMerge alle 3 Felder als Input, und directiveA erhält nur "field1":
Und für diese Query:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}...erhalten die Directives @validate und @resolveValueAndMerge alle 3 Felder als Input, directiveA erhält nur "field1", directiveB erhält nur "field2", und directiveC erhält "field2" und "field3":
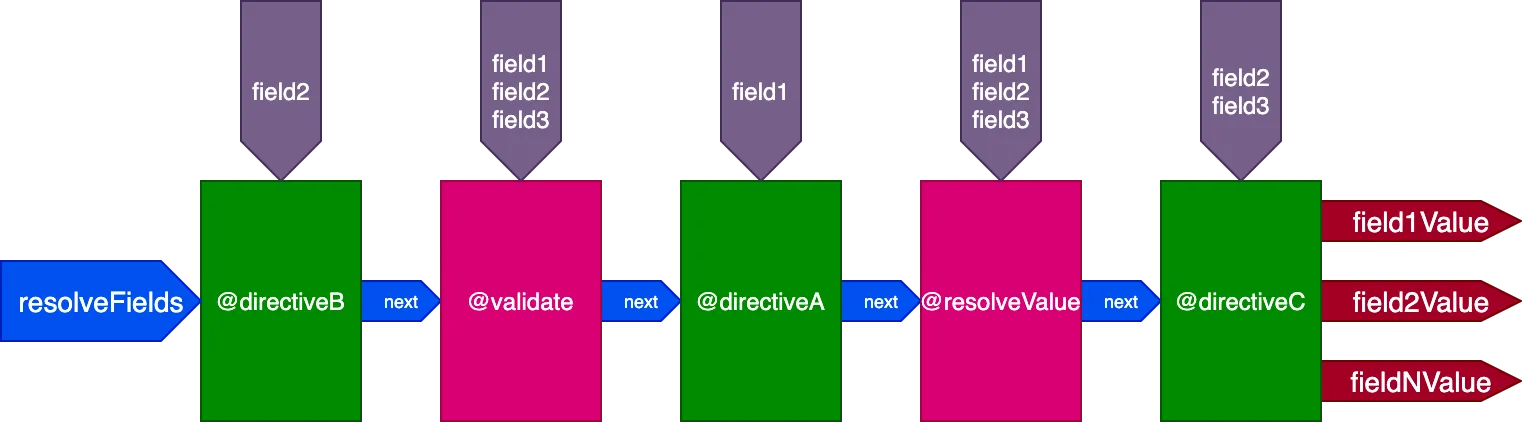
Die Directive-Ausführung ID für ID steuern
Bisher konnte eine Directive in einer bestimmten Stufe die Ausführung von Directives in späteren Stufen über ein Flag skipExecution beeinflussen. Dieses Flag ist jedoch für alle Fälle nicht granular genug.
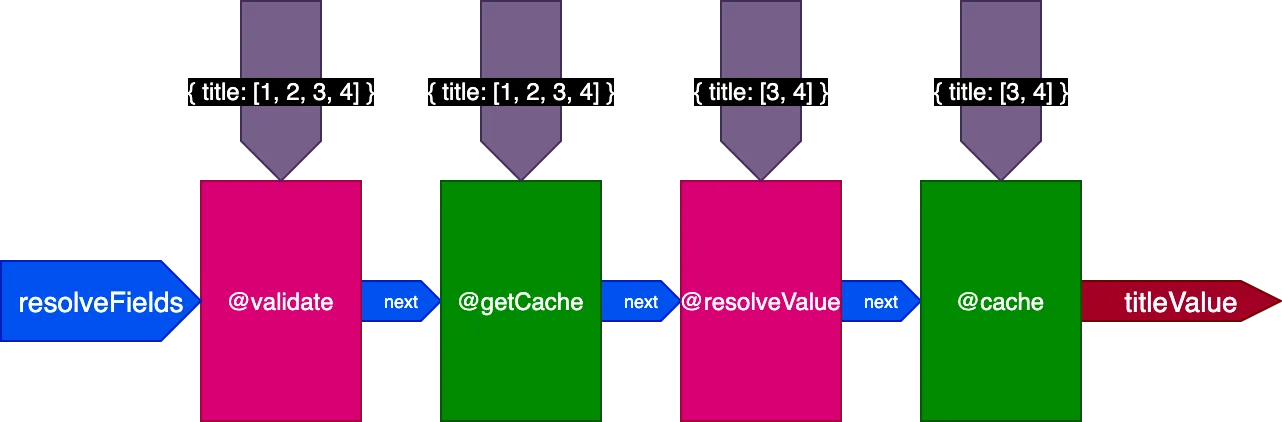
Betrachten wir zum Beispiel eine @cache-Directive, die im "end"-Slot platziert ist, um den Feldwert zu speichern, sodass beim nächsten Abfragen des Felds sein Wert über eine @getCache-Directive im "middle"-Slot aus dem Cache abgerufen werden kann:
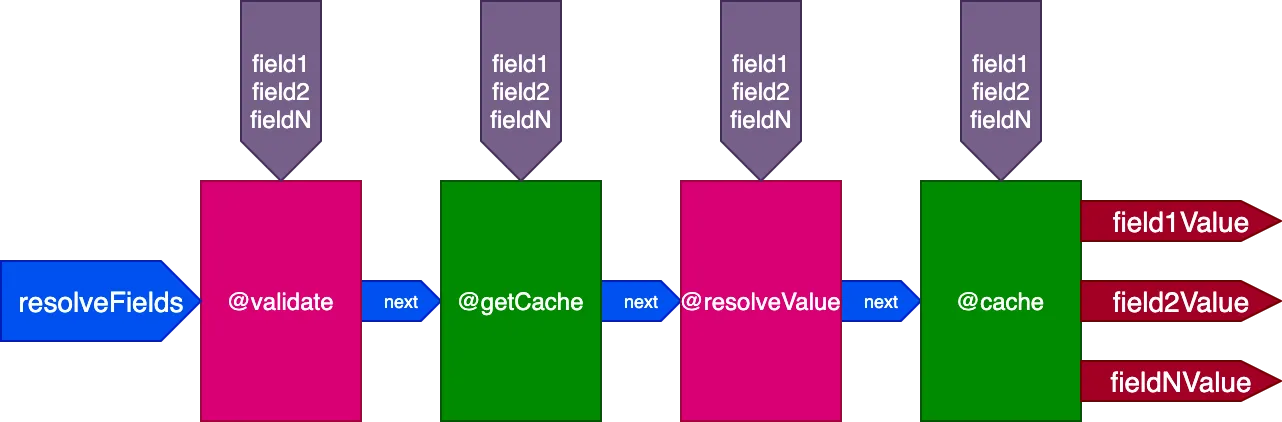
Beim Ausführen dieser Query:
{
posts(pagination: { limit: 2 }) {
title @translate @cache
}
}Ruft der Server 2 Datensätze ab und speichert sie im Cache. Dann führen wir dieselbe Query aus, aber auf 4 Datensätze angewendet:
{
posts(pagination: { limit: 4 }) {
title @translate @cache
}
}Bei der Ausführung dieser 2. Query waren die 2 Datensätze der 1. Query bereits gecacht, die anderen 2 jedoch nicht. Wir bräuchten jedoch alle 4 Datensätze bereits gecacht, um das Flag skipExecution verwenden zu können. Es wäre besser, wenn wir die ersten 2 Datensätze aus dem Cache abrufen und nur die anderen 2 Datensätze auflösen könnten.
Daher aktualisieren wir das Pipeline-Design erneut. Wir ersetzen das Flag skipExecution und übergeben stattdessen jeder Directive die Liste der Objekt-IDs pro Feld, auf die die Directive angewendet werden soll, über ein fieldIDs-Input-Objekt:
{
field1: [ID11, ID12, ...],
field2: [ID21, ID22, ...],
...
fieldN: [IDN1, IDN2, ...],
}Die Variable fieldIDs ist für jede Directive eindeutig, und jede Directive kann die fieldIDs-Instanz für alle Directives in späteren Stufen ändern. Dann kann skipExecution granular auf ID-Basis durchgeführt werden, indem die ID einfach aus fieldIDs für alle nachfolgenden Directives im Stack entfernt wird.
Die Pipeline sieht nun so aus:
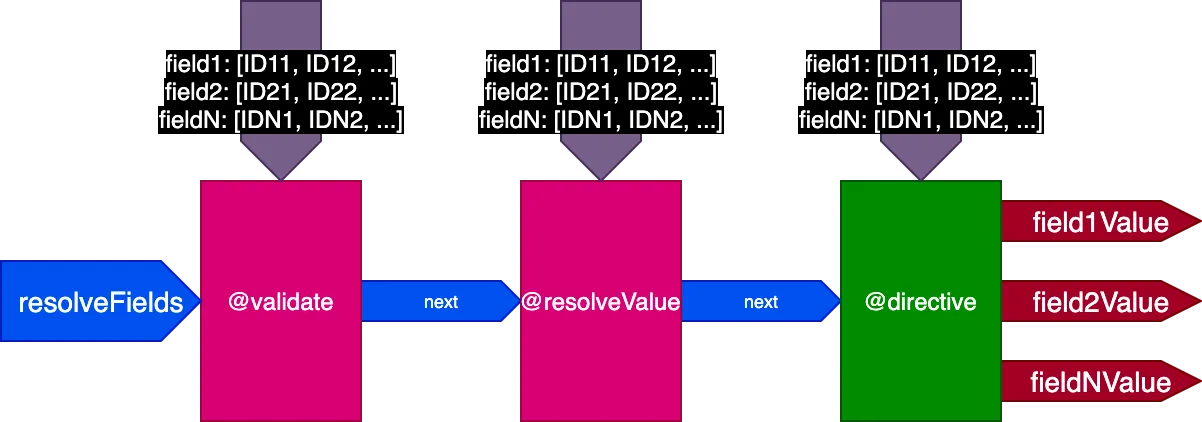
Auf das vorherige Beispiel angewendet sieht die Pipeline beim Ausführen der ersten Query mit 2 Datensätzen so aus:
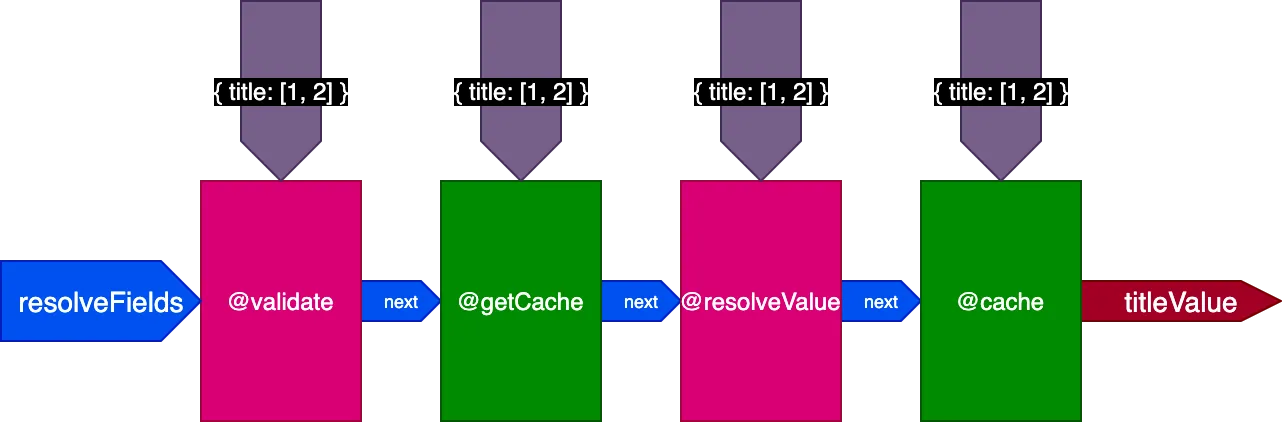
Bei der Ausführung der zweiten Query mit 4 Datensätzen erhält die Directive @getCache die IDs aller 4 Datensätze, aber sowohl @resolveValueAndMerge als auch @cache erhalten nur die IDs der letzten 2 Datensätze (die nicht gecacht sind):
Alles zusammenfügen
Dies ist das endgültige Design der Directive-Pipeline:
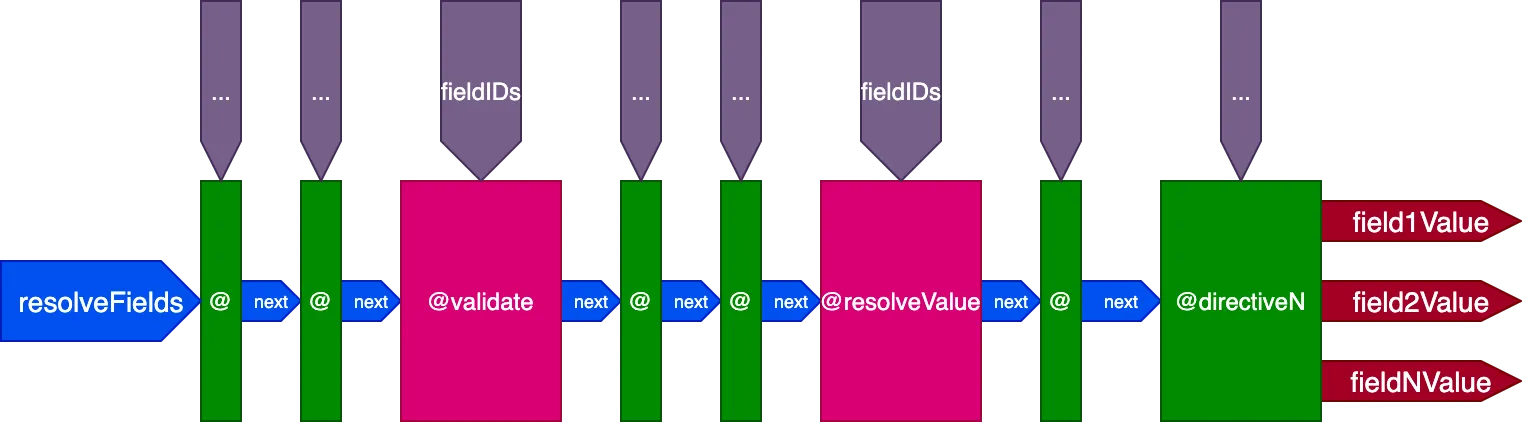
Zusammenfassend sind dies ihre Eigenschaften:
- Field-Resolver werden von innerhalb der Directive-Pipeline aufgerufen, über die Directives
@validateund@resolveValueAndMerge - Directives können in einem der 5 Slots platziert werden:
"beginning","before-validate","middle","after-validate"und"end" - Directives lösen mehrere Felder in einem einzigen Aufruf auf
- Eine einzelne Pipeline enthält alle an der Query beteiligten Directives
- Jede Directive erhält ihre eigene Menge von IDs, die pro Feld über die Variable
fieldIDsaufzulösen sind - Directives können die Variable
fieldIDsfür alle Directives in einer späteren Stufe der Pipeline ändern