
Die Reihenfolge der Field-Auflösung steuern
Das Ziel der @export-Direktive, die von Multiple Query Execution bereitgestellt wird, ist es, den Wert eines Fields (oder einer Menge von Fields) in eine Variable zu exportieren, die an anderer Stelle in der Query verwendet werden kann.
Diese Direktive würde nicht funktionieren, wenn das Lesen der Variable stattfindet, bevor der Wert in die Variable exportiert wurde. Daher muss die Engine eine Möglichkeit bieten, die Ausführungsreihenfolge der Fields zu steuern.
Gato GraphQL bietet eine Möglichkeit, die Ausführungsreihenfolge der Fields über die Query selbst zu steuern. Die Engine lädt Daten in Iterationen für jeden Typ, löst dabei zuerst alle Fields des ersten Typs auf, den sie in der Query antrifft, dann alle Fields des zweiten Typs und so weiter, bis keine weiteren Typen mehr zu verarbeiten sind.
Zum Beispiel die folgende Query mit Objekten vom Typ Director, Film und Actor:
{
directors {
name
films {
title
actors {
name
}
}
}
}...wird von der GraphQL-Engine in dieser Reihenfolge aufgelöst:

Wenn ein Typ nach seiner Verarbeitung in der Query erneut referenziert wird, um noch nicht geladene Daten abzurufen (z. B. von zusätzlichen Objekten oder zusätzlichen Fields bereits geladener Objekte), wird der Typ am Ende der Iterationsliste erneut hinzugefügt.
Wenn wir zum Beispiel auch das Field preferredDirector des Actor abfragen (das ein Objekt vom Typ Director zurückgibt):
{
directors {
name
films {
title
actors {
name
preferredDirector {
name
}
}
}
}
}...dann verarbeitet die GraphQL-Engine die Query in dieser Reihenfolge:

Schauen wir uns an, wie sich das bei der Ausführung von @export in einer einzelnen Query verhält. Beim ersten Versuch erstellen wir die Query so, wie wir es normalerweise tun würden, ohne an die Ausführungsreihenfolge der Fields zu denken:
query GetPostsAuthorNames {
user(by: { id: 1 }) {
name @export(as: "authorName")
}
posts(filter: { search: $authorName }) {
id
title
}
}Beim Ausführen der Query ergibt sich diese Antwort:
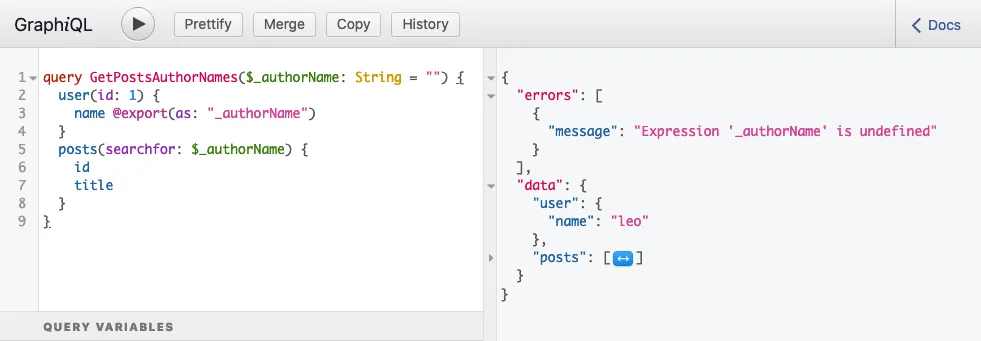
...die den folgenden Fehler enthält:
{
"errors": [
{
"message": "Expression 'authorName' is undefined",
}
]
}Dieser Fehler bedeutet, dass die Variable $authorName noch nicht gesetzt war, als sie gelesen wurde; sie war undefined.
Schauen wir uns an, warum das passiert. Zunächst analysieren wir, welche Typen in der Query vorkommen, unten als Kommentare hinzugefügt:
# Type: Root
query GetPostsAuthorNames {
# Type: User
user(by: {id: 1}) {
# Type: String
name @export(as: "authorName")
}
# Type: Post
posts(filter: { search: $authorName }) {
# Type: ID
id
# Type: String
title
}
}Um die Typen zu verarbeiten und ihre Daten zu laden, fügt die Data-Loading-Engine den Query-Typ Root in eine FIFO-Liste (First-In, First-Out) ein, sodass [Root] die initiale Liste ist, die dem Algorithmus übergeben wird. Anschließend wird sequenziell über die Typen iteriert:
| # | Operation | Liste |
|---|---|---|
| 0 | FIFO-Liste vorbereiten | [Root] |
| 1a | Ersten Typ der Liste entfernen (Root) | [] |
| 1b | Alle abgefragten Fields des Typs Root verarbeiten:→ user(by: {id: 1})→ posts(filter: { search: $authorName })Ihre Typen ( User und Post) zur Liste hinzufügen | [User, Post] |
| 2a | Ersten Typ der Liste entfernen (User) | [Post] |
| 2b | Das abgefragte Field des Typs User verarbeiten:→ name @export(as: "authorName")Da es ein skalarer Typ ( String) ist, muss er nicht zur Liste hinzugefügt werden | [Post] |
| 3a | Ersten Typ der Liste entfernen (Post) | [] |
| 3b | Alle abgefragten Fields des Typs Post verarbeiten:→ id→ titleDa es skalare Typen ( ID und String) sind, müssen sie nicht zur Liste hinzugefügt werden | [] |
| 4 | Liste ist leer, Iteration endet. |
Hier sehen wir das Problem: @export wird in Schritt 2b ausgeführt, wurde aber in Schritt 1b gelesen.
Genau hier müssen wir den Field-Ausführungsfluss steuern. Die implementierte Lösung besteht darin, den Zeitpunkt zu verzögern, zu dem die exportierte Variable gelesen wird. Dies wird erreicht, indem das Field self vom Typ Root künstlich abgefragt wird.
Das Field self gibt, wie der Name sagt, dasselbe Objekt zurück; auf das Root-Objekt angewendet, gibt es dasselbe Root-Objekt zurück. Du fragst dich vielleicht: "Wenn ich das Root-Objekt bereits habe, warum sollte ich es erneut abrufen?". Weil der Algorithmus der Engine dann diesen neuen Verweis auf Root am Ende der FIFO-Liste hinzufügen muss, und wir die abgefragten Fields gezielt vor oder nach jeder dieser Iterationen verteilen können.
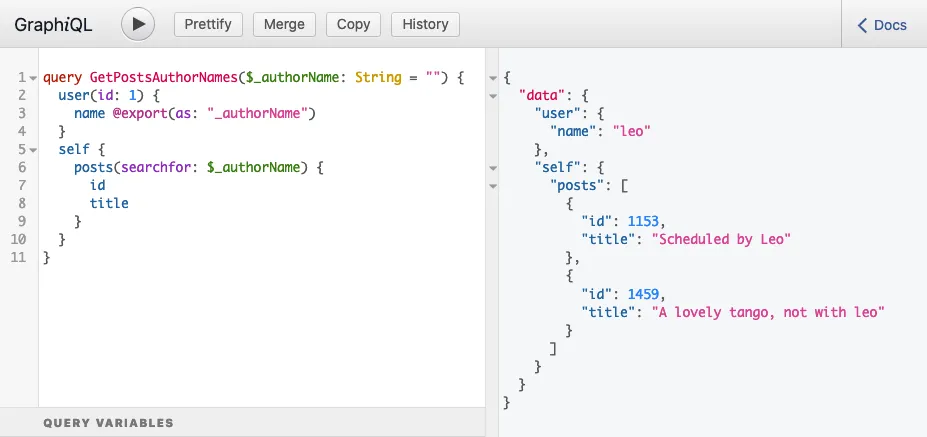
Deshalb wird das Field posts(filter:{ search: $authorName }) in der obigen Query in ein self-Field eingebettet, und das Ausführen der Query liefert die erwartete Antwort:
query GetPostsAuthorNames {
user(by: {id: 1}) {
name @export(as: "authorName")
}
self {
posts(filter: { search: $authorName }) {
id
title
}
}
}
Schauen wir uns die Reihenfolge an, in der die Typen für diese Query verarbeitet werden, um zu verstehen, warum sie korrekt funktioniert:
| # | Operation | Liste |
|---|---|---|
| 0 | FIFO-Liste vorbereiten | [Root] |
| 1a | Ersten Typ der Liste entfernen (Root) | [] |
| 1b | Alle abgefragten Fields des Typs Root verarbeiten:→ user(by: {id: 1})→ selfIhre Typen ( User und Root) zur Liste hinzufügen | [User, Root] |
| 2a | Ersten Typ der Liste entfernen (User) | [Root] |
| 2b | Das abgefragte Field des Typs User verarbeiten:→ name @export(as: "authorName")Da es ein skalarer Typ ( String) ist, muss er nicht zur Liste hinzugefügt werden | [Root] |
| 3a | Ersten Typ der Liste entfernen (Root) | [] |
| 3b | Das abgefragte Field des Typs Root verarbeiten:→ posts(filter:{ search: $authorName })Seinen Typ ( Post) zur Liste hinzufügen | [Post] |
| 4a | Ersten Typ der Liste entfernen (Post) | [] |
| 4b | Alle abgefragten Fields des Typs Post verarbeiten:→ id→ titleDa es skalare Typen ( ID und String) sind, müssen sie nicht zur Liste hinzugefügt werden | [] |
| 5 | Liste ist leer, Iteration endet. |
Jetzt können wir sehen, dass das Problem gelöst wurde: @export wird in Schritt 2b ausgeführt und in Schritt 3b gelesen.
Multiple Query Execution macht genau das beim Entkoppeln von queries: Es konvertiert das GraphQL-Dokument und fügt self-Fields hinzu, damit die Fields jeder Operation erst ausgeführt werden, nachdem alle Fields aller vorherigen Operationen aufgelöst wurden.